I Tried Building an ISO 27001 ISMS with ChatGPT. Then I Used Rakenne. Night and Day.
How Rakenne's ISO 27001 skills maintain cross-document consistency, catch risk scoring errors, and enforce end-to-end traceability — where ChatGPT silently produces audit failures.
ISO 27001 isn’t one document — it’s a system of interdependent artifacts where a mistake in the risk register cascades through every downstream deliverable. That makes it the perfect stress test for AI compliance tools.
I ran the same company profile through ChatGPT and Rakenne to see which one could actually produce audit-ready ISMS documentation.
Why ISO 27001 Is Harder Than SOC 2
I previously compared ChatGPT and Rakenne on SOC 2 control narratives . SOC 2 narratives are largely independent — each control stands on its own. You can fix one without breaking another.
ISO 27001 is a management system. The documents form a dependency graph:
- The organization profile establishes context — tech stack, locations, regulations, data types
- The risk assessment identifies threats and scores them against that context
- The Statement of Applicability (SoA) maps all 93 Annex A controls to In/Out, driven by risk treatment decisions
- The policy set (10+ documents) implements the controls, cross-referencing each other by document ID
- The internal audit and management review assess the entire system
Every document references the others. An auditor will trace threads from risk through treatment to control to policy to evidence. Inconsistency isn’t a style issue — it’s a nonconformity finding.
The Setup
My test company: A 200-person fintech running AWS and Azure (hybrid cloud), with an in-house engineering team of 35, processing EU customer data under GDPR. Targeting ISO 27001:2022 certification with a Stage 1 audit in 12 weeks.
The deliverables: Risk assessment (methodology + register + treatment plan), Statement of Applicability (all 93 controls), and the core policy set (information security policy, access control, incident management, and four more procedures).
Round 1: ChatGPT (GPT-4)
I gave ChatGPT the full company profile and asked it to produce the risk assessment, SoA, and information security policy in sequence. I maintained context within a single conversation.
The Risk Assessment
ChatGPT produced a risk methodology, identified 22 risks, scored them on a 5x5 matrix, and proposed treatment with Annex A controls. It took about 90 seconds. The problems started when I looked closely.
Residual risk scores higher than inherent risk. Three risks had residual impact or likelihood scores higher than their inherent scores. Risk R-009 had inherent risk of 3x3=9 but residual risk of 3x4=12. That’s a logical impossibility — treatment can’t make a risk worse. An auditor would catch this instantly and question the entire methodology.
Duplicate risks inflating the register. Two entries described nearly identical threats: “unauthorized access to customer data” and “unauthorized access to client information.” Same threat, different wording. A bloated register isn’t just sloppy — it creates confusion about which entry owns the treatment decision.
Internal contradictions. The methodology section specified “quarterly risk reviews,” but the treatment plan referenced “annual reassessment.” An auditor would ask which one it actually is.
The Statement of Applicability
Excluded controls that contradict the company profile. Controls A.8.25 through A.8.34 (secure development lifecycle) were excluded with “Not applicable.” But my company profile explicitly mentioned a 35-person engineering team building software. An auditor would challenge every one of those exclusions.
No real evidence links. Twelve included controls listed “See information security policy” as implementation evidence. That’s not evidence — it’s a pointer to a document that may or may not address the specific control. An auditor expects to see which section of which document implements which control.
Broken traceability. The SoA referenced “the Risk Treatment Plan” but used different risk IDs than the assessment document. The thread from risk to control was severed.
The Policies
Inconsistent role titles. The Information Security Policy referred to the “Chief Information Security Officer.” The Access Control Procedure mentioned the “Security Manager.” Same role, different title. Auditors flag this because it signals the documents weren’t written as a coherent set.
Hallucinated regulatory requirements. The Incident Management Procedure required “notification within 24 hours” for data breaches. GDPR requires 72 hours. ChatGPT invented a stricter timeline that doesn’t match the regulation my company actually needs to comply with.
Unfilled placeholders. Multiple policies contained [Organization Name], [YYYY-MM-DD], and [PROC-XXX] — ChatGPT generated templates, not finished documents. I’d need to find and replace every one manually, and hope I didn’t miss any.
No cross-reference integrity. The Corrective Action Procedure referenced “PROC-003 Incident Management” but the Incident Management Procedure was numbered “PROC-005.” Document IDs didn’t match across the set.
Time spent: gave up after 6+ hours
Every fix in one document created a ripple in the others. Fixing the risk scores meant updating the treatment plan, which meant updating the SoA justifications, which meant updating policy references. I was the integration layer, and I was failing at it.
Round 2: Rakenne
Rakenne breaks ISO 27001 into specialized skills — organization profile, risk assessment, SoA, policy generator, gap assessment, internal audit, annual maintenance, and more. Each skill produces structured output that downstream skills consume. Here’s what happened.
The Organization Profile Propagates Everywhere
I started with the Organization Profile skill. It asked about our tech stack, locations, departments, regulatory obligations, and data types. When I mentioned “AWS and Azure,” the technology_stack_normalizer tool classified each service by deployment model (IaaS, PaaS, SaaS) and flagged that I hadn’t specified data residency regions — a detail auditors always ask about.
That profile became the single source of truth for every subsequent skill. When the Policy Generator ran later, its terminology_consistency_checker tool automatically verified that every policy referenced “AWS” and “Azure” consistently — not “cloud infrastructure” in one place and “AWS” in another. It caught and replaced every [Organization Name] placeholder with our actual company name using the profile data.
With ChatGPT, I mentioned “AWS and Azure” in my initial prompt. Some outputs used both names, others said “cloud provider.” There was no mechanism to enforce consistency.
Validation Tools Caught What I Would Have Missed
The Risk Assessment skill uses six validation tools that run after the register and treatment plan are drafted. Here’s what they caught:
residual_risk_validator flagged two risks where residual scores exceeded inherent scores — the same logical error ChatGPT produced silently. It also flagged a “Critical” risk I’d marked as “Accept” without documented management approval, which violates Clause 6.1.3(e). The agent rewrote the scores and added the approval requirement before I even saw the final output.
risk_deduplication_engine identified three risk entries with >80% token similarity. I merged them, keeping the most complete description. ChatGPT produced similar duplicates but had no way to detect them.
asset_risk_coverage_validator cross-referenced our asset inventory (from a previous skill) and found that two assets classified as “Confidential” — the customer database and payment processing system — had no corresponding entries in the risk register. I’d simply forgotten them. Without this tool, those gaps would have survived until the Stage 2 audit.
risk_entry_validator caught a risk entry where I’d specified “Treat” as the treatment option but hadn’t mapped it to any Annex A controls. The agent prompted me for the mapping before proceeding.
These aren’t nice-to-have checks. Every one of them represents a finding an auditor would raise. The tools forced the agent to self-correct before producing final output.
The SoA Stayed Consistent with Scope and Risks
When I moved to the Statement of Applicability skill, it loaded the risk assessment automatically and ran suggest_soa_inclusions to bootstrap control selection from the risk themes it found. No re-entering context.
After I drafted the SoA, soa_consistency_checker ran three cross-document checks:
Scope consistency: I’d excluded A.5.23 (cloud security). The tool flagged that my risk register contained three cloud-related risks — I needed to either include the control or explain why those risks were treated differently. With ChatGPT, the contradiction between excluding cloud controls and having cloud risks passed silently.
Risk traceability: The tool verified that every control marked “applicable” could trace back to a risk treatment decision. It found two controls I’d included “for best practice” without linking them to specific risks — valid, but the tool flagged them so I could add the rationale an auditor would expect.
Evidence file existence: With
policy_dirpointed at the output directory, the tool checked that referenced policy files actually existed. Three controls pointed to an “Asset Management Procedure” that hadn’t been generated yet — the tool told me to create it before finalizing.Implementation status tracking: The SoA now includes an optional Implementation status column (Not Started / Planned / Implemented / Verified) that tracks where each control sits in the implementation lifecycle. The consistency checker summarized the distribution — 34 controls Not Started, 28 Planned, 14 Implemented, 2 Verified — giving a clear picture of progress. The justification audit flagged 12 controls that had evidence linked but were still marked “Not Started”, prompting me to update their status. ChatGPT has no equivalent — it treats the SoA as a static document with no lifecycle awareness.
Policies Referenced Each Other Correctly
The Policy Generator skill produces documents in a deliberate order — Information Security Policy first (it’s referenced by everything else), then Document Control, Risk Management, and so on through the full set.
After generating each document, four validation tools run in sequence:
document_metadata_validatorchecks Clause 7.5 compliance — document ID, version, dates, owner, approval authority, change history. Every field must be filled.mandatory_topic_checkerverifies that the document covers all required topics for its type. An Access Control Procedure must address user registration, privilege management, authentication, and access review. If a topic is missing, the agent adds it.citation_converterturns internal ISO clause comments into visible citations — so the auditor can see exactly which clause each section addresses.terminology_consistency_checkerverifies no placeholder text remains, normative language is consistent (“shall” for requirements, “should” for recommendations), and role titles match across all documents.
After all policies are generated, treatment_to_policy_validator runs a final cross-check: every “Treat” decision in the risk treatment plan must have a corresponding policy file. It found two treatment decisions pointing to procedures that hadn’t been created yet. The agent generated them before declaring the set complete.
End-to-End Traceability
The SoA skill’s risk_control_evidence_matrix produced the artifact auditors love most: a traceability table mapping every risk ID through its Annex A control to the evidence file path, with existence and freshness checks.
Risk R-003 → A.5.15 (Access control) → output/Access-Control-Procedure.md → EXISTS → Modified 2026-03-12
Risk R-007 → A.5.24 (Incident management) → output/Incident-Management-Procedure.md → EXISTS → Modified 2026-03-12
Risk R-012 → A.5.29 (Business continuity) → output/Business-Continuity-Procedure.md → MISSING
That last line told me I hadn’t generated the Business Continuity Procedure yet. With ChatGPT, I would have discovered this gap when the auditor asked for it.
The Dashboard
Rakenne tracks progress across all ISO 27001 skills in a single view:
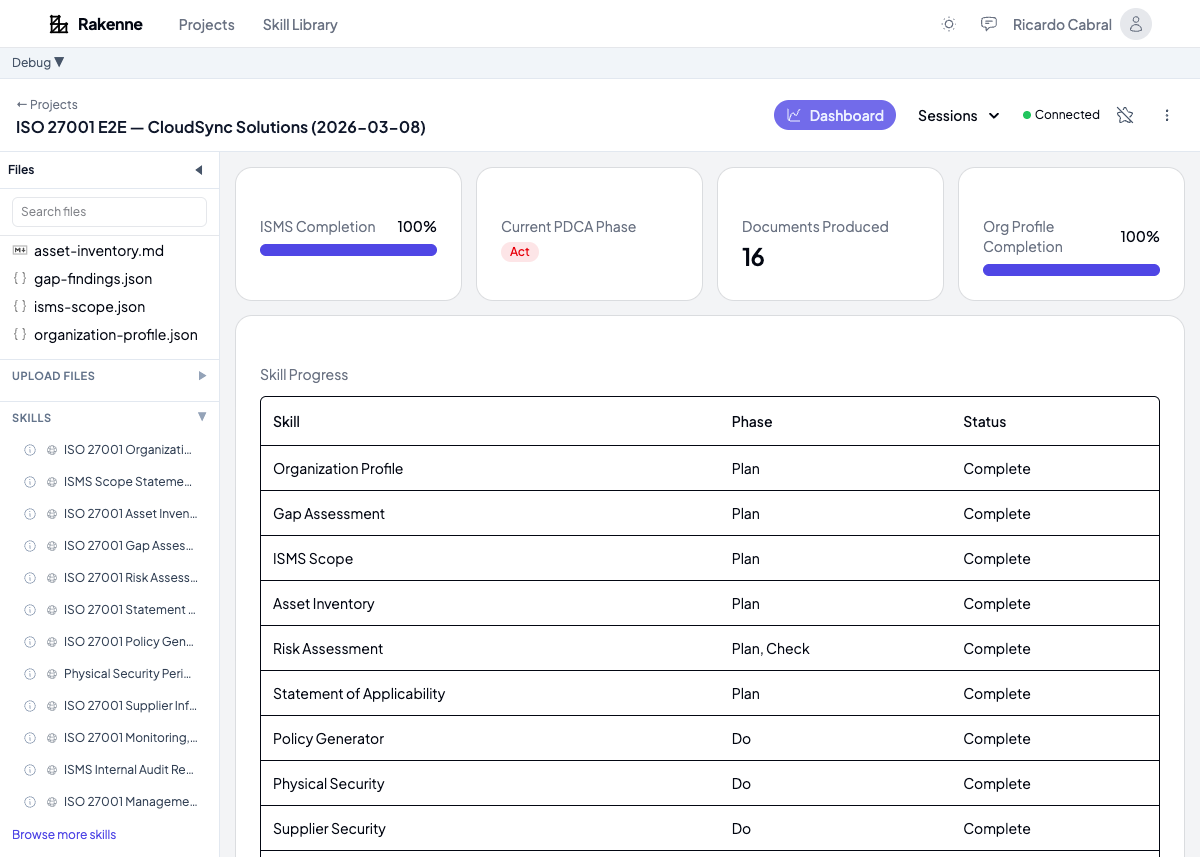
The dashboard shows which skills are complete, how many risks are identified and treated, how many of the 93 Annex A controls have evidence, and what percentage of mandatory policies exist. When you’re preparing for certification, this is the view your consultant wants to see — not a folder of disconnected documents.
Time spent: ~3 hours across all skills
- 20 minutes on the organization profile
- 45 minutes on risk assessment (answering questions + reviewing validation findings)
- 30 minutes on the SoA (reviewing suggested inclusions, adding exclusion rationale)
- 60 minutes on the policy set (reviewing each document, addressing validation findings)
- 25 minutes on cross-document checks and dashboard review
The Comparison
| Dimension | ChatGPT | Rakenne |
|---|---|---|
| Time to usable output | 6+ hours (gave up) | ~3 hours across all skills |
| Cross-document consistency | Manual reconciliation required | Enforced by shared context and validation tools |
| Risk scoring errors | Passed silently (residual > inherent) | Caught and corrected by residual_risk_validator |
| Duplicate risks | Undetected | Caught by risk_deduplication_engine |
| SoA vs. scope contradictions | Excluded cloud controls despite cloud risks | Caught by soa_consistency_checker |
| Implementation progress | SoA is a static In/Out list — no lifecycle tracking | Implementation status column (Not Started → Planned → Implemented → Verified) with automated summaries |
| Placeholder text in policies | [Organization Name] remained in output | Caught and replaced by terminology_consistency_checker |
| Evidence traceability | Non-existent | End-to-end matrix from risk to evidence file |
| Asset coverage gaps | Confidential assets missing from risk register | Caught by asset_risk_coverage_validator |
| Role title consistency | “CISO” in one doc, “Security Manager” in another | Enforced across all documents |
| Regulatory accuracy | Hallucinated 24h breach notification (GDPR = 72h) | Tailored to regulations from organization profile |
| Progress tracking | None | Integrated dashboard across all ISMS skills |
The Bottom Line
ChatGPT is a text generator. It can produce any single ISO 27001 document in isolation — and it will look plausible. But it can’t maintain consistency across a document set, validate risk scores against logical rules, cross-reference controls against scope, check that referenced policy files exist, or trace the thread from risk through treatment to evidence.
For ISO 27001, those aren’t nice-to-haves. They’re the difference between passing and failing your certification audit.
Rakenne encodes the ISO 27001 workflow — what to ask, what to produce, what to validate, how documents connect. The agent doesn’t just generate text. It builds an ISMS, checks its own work, and tells you what’s missing before the auditor does.
Try It Yourself
Rakenne’s ISO 27001 skills are available with no signup required. Start with the Organization Profile, then work through Risk Assessment, SoA, and Policy Generation. See how the validation tools catch issues ChatGPT would miss.
This post compares outputs from a test conducted in March 2026. Both tools are updated frequently — your results may vary. The comparison reflects ISO 27001 ISMS documentation and is not a comprehensive evaluation of either platform.
Try it yourself
Open a workspace with the skills described in this article and start drafting in minutes.
Get Started Free — No Sign-Up